

Soluzioni OCR per Ubuntu Linux
 Come si sa, nel mondo Linux e opensource, è possibile trovare ottime soluzioni per qualunque necessità, quindi non possono mancare gli OCR, ovvero quei software che permettono di riconoscere il testo all'interno di immagini per poterlo esportare e poi lavorare all'interno di un editor di testo.
Come si sa, nel mondo Linux e opensource, è possibile trovare ottime soluzioni per qualunque necessità, quindi non possono mancare gli OCR, ovvero quei software che permettono di riconoscere il testo all'interno di immagini per poterlo esportare e poi lavorare all'interno di un editor di testo.
In quest'articolo voglio presentare tre diverse soluzioni OCR per Ubuntu Linux presenti nei repository ufficiali o in altri PPA.
GImageReader
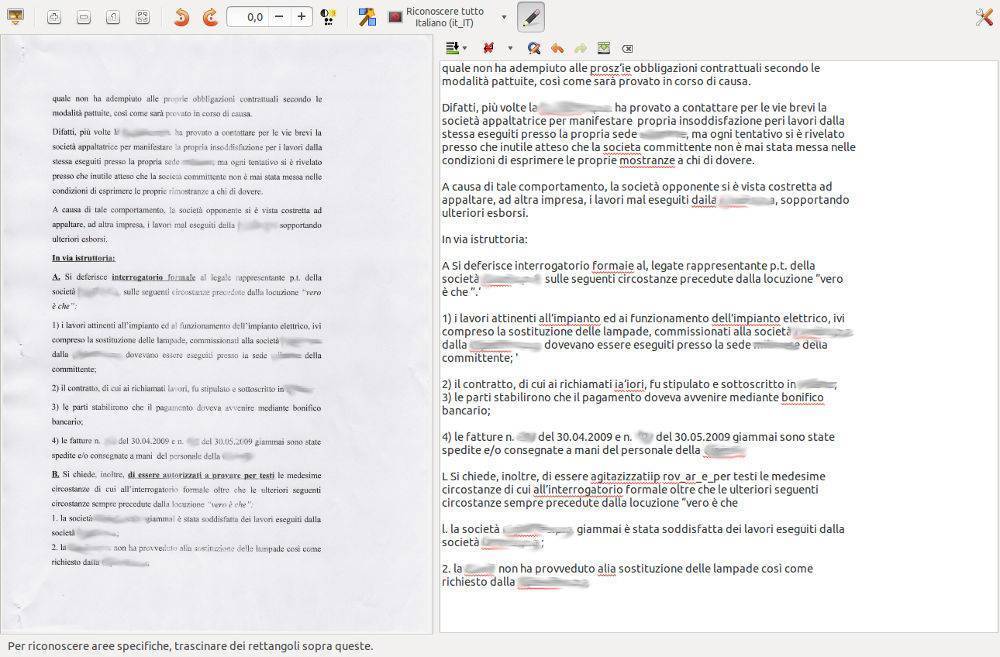
Come si nota dall'immagine, GImageReader ha un'interfaccia semplice ed intuitiva.
E' opensource ed è disponibile anche per Windows oltre che per Linux.
Per il riconoscimento dei caratteri utilizza Tesseract di Google.
Può lavorare su scansioni dirette dal nostro scanner oppure su PDF ed immagini Tiff, Gif, Jpg e Png.
Supporta varie lingue tra cui l'italiano e permette di esportare il risultato in un file di testo.
Tra le varie funzioni c'è la possibilità di modificare i gradi di inclinazione del documento scansionato per migliorarne il riconoscimento.
Per installarlo eseguire i seguenti comandi:
sudo add-apt-repository ppa:sandromani/gimagereader sudo apt-get update sudo apt-get install gimagereader tesseract-ocr tesseract-ocr-ita
OCRFeeder
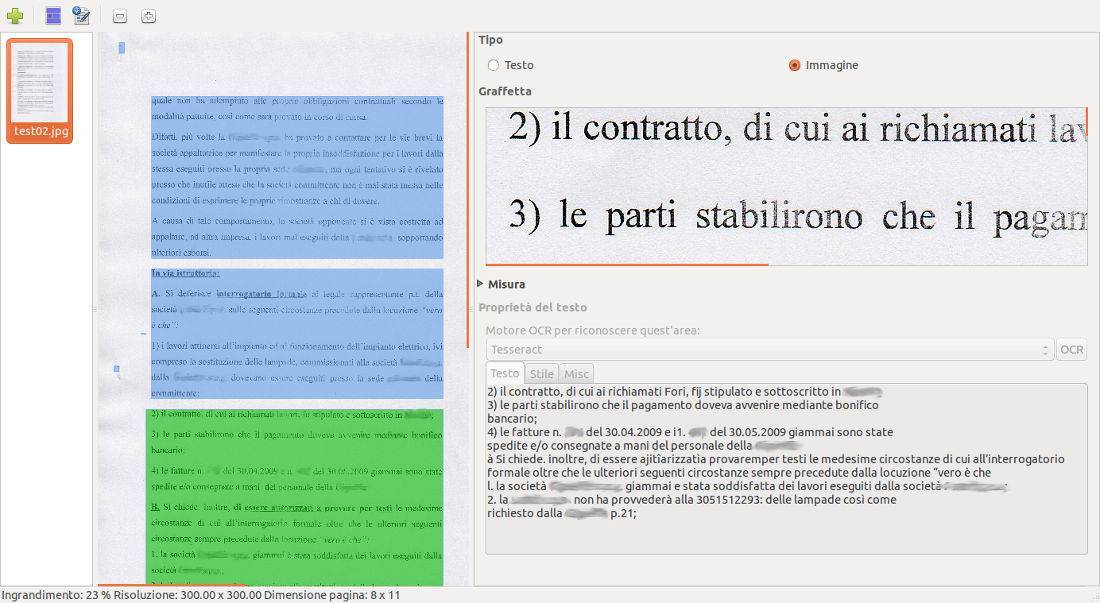
Come si nota dall'immagine, anche OCRFeeder ha un'interfaccia semplice ed intuitiva.
Anche questo software per il riconoscimento dei caratteri utilizza Tesseract di Google, però è possibile fargli aggiungere altri motori di riconoscimento (Strumenti -> Motori OCR).
Può lavorare su scansioni dirette dal nostro scanner oppure su PDF (da importate tramite la voce di menu File -> Importa PDF) e vari formati di immagini tra cui JPEG.
Supporta varie lingue tra cui l'italiano e permette di esportare il risultato nei seguenti formati:
- file di testo semplice
- ODT OpenDocument, quindi gestibili direttamente con LibreOffice o OpenOffice.org
- HTML
Tra le varie funzioni c'è la possibilità di raddrizzare il documento tramite la voce di menu Strumenti -> Raddrizza immagine.
Si installa direttamente dai repository di Ubuntu. E' importante installare anche il pacchetto tesseract-ocr-ita per avere il riconoscimento con la lingua italiana.
YAGF-Yet Another Graphical Front-end
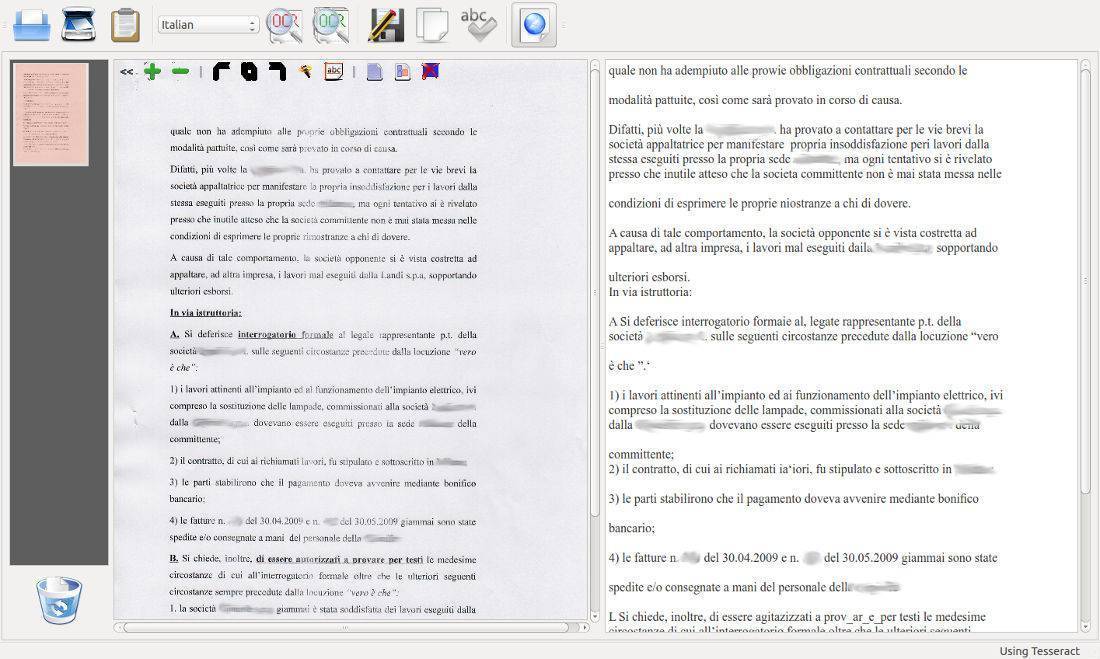
YAGF è un front-end grafico per i motori OCR cuneiform e tesseract.
Come si nota dall'immagine, YAGF ha un'interfaccia leggermente più ricca delle precedenti soluzioni.
Può lavorare su scansioni dirette dal nostro scanner oppure vari formati di immagini: PNG, JPEG, BMP, TIFF, GIF, PNM, PGM, PBM e PPM. Inoltre premette di importare PDF (File -> Import from PDF)
Supporta varie lingue tra cui l'italiano e permette di esportare il risultato nei seguenti formati:
- file di testo semplice
- HTML
Tra le varie funzioni offerte ci sono:
- la possibilità di incollare un'immagine dalla clipboard
- funzioni per preparare l'immagine per il riconoscimento
Si installa direttamente dai repository di Ubuntu.
Conclusione
Tutte le soluzioni utilizzano lo stesso motore OCR e di conseguenza il risultato è molto simile.
Il riconoscimento è buono ma non ottimo e ovviamente migliora in base alla qualità della scansione.
Comunque, tra i 3, quello che mi ha dato risultati leggermente migliori è GImageReader che peraltro, come si nota dall'immagine, sottolinea i termini scorretti in base al controllo ortografico e ne permette la modifica prima del salvataggio in file di testo.
Quello che mi ha dato risultati peggiori (anche se di pochissimo) è OCRFeeder che però è l'unico che permette l'esportazione diretta in file OpenDocument (ODT).
In ogni caso le differenze sono veramente minime, quindi sono le varie funzionalità a far scegliere uno o l'altro in base alle proprie preferenze.
Buongiorno,
vorrei sapere come integrare il testo riconosciuto direttamente sul pdf esistente? Funzione che svolge Adobe Acrobat Pro con il suo OCR.